[신입OJT] 모든 개발자를 위한 HTTP 웹 기본 지식
**모든 자료와 내용은 인프런 김영한 지식공유자의 '모든 개발자를 위한 http 웹 기본지식'의 출처입니다.
Section1. 인터넷 네트워크
- IP (인터넷 프로토콜)
- 지정한 IP주소에 데이터를 전달하는데, 패킷이라는 통신단위로 데이터를 전달한다.

IP 프로토콜의 한계 :
1. 비연결성 : 패킷 받을 대상의 상태에 관계없이 전송됨
2. 비신뢰성 : 중간에 패킷이 사라지거나, 순서대로 안가는경우가 존재
3. 프로그램 구분 : 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 둘 이상이면 어쩌지..?
- TCP / UDP
- 인터넷 프로토콜 스택에는 4계층이 있다 .. !

- 내가 메시지를 하나 보낸다고 할때 프로토콜의 작동원리는 어떻게 될까?

- 그림을 자세히 봐보면, ip 프로토콜로 해결되지 않았던 문제들이 tcp 프로토콜을 이용하면서 해결이 되었다.
- TCP의 특징 :
1. 전송제어 프로토콜이다 (Transmission Control Protocol)
2. TCP 3 way handshake(SYN , SYN+ACK, ACK/ 신신액액) 를 사용하면서 연결지향적이다.
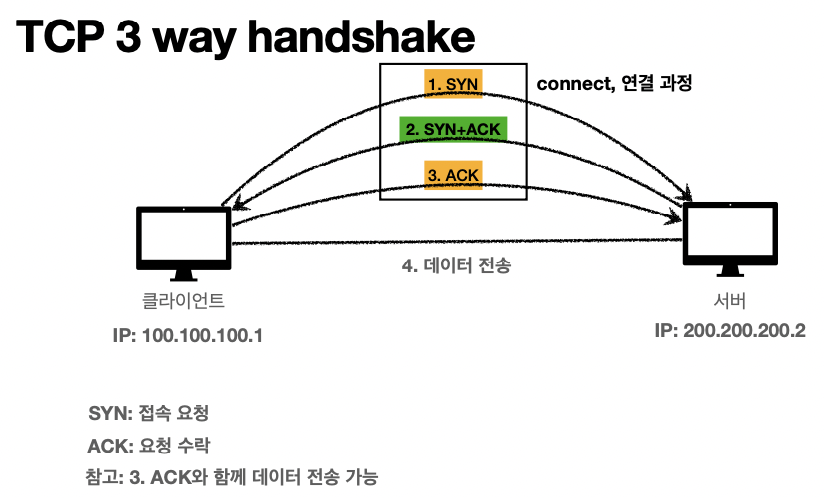
3. 데이터 전달을 보증 : 클라이언트에서 서버에 전달을 하면 전달을 잘 받았는지 응답을 보내준다.
4. 순서를 보장 : 패킷 순서가 잘못 도착하면, 틀린 순서부터 다시 보내라는 요청을 한다.
이것들이 그냥 가능한게 아니라,, tcp안에 많은 정보들이 이렇게 들어있기 때문이다. .. !!

- UDP의 특징 :
: 사용자 데이터그램 프로토콜 ( User Datagram Protocol)
: 기능이 거의 없지만, IP와 같은 기능을한다. +PORT정보 +체크성을 추가해준다
: (하나의 OS위에서 여러개의 애플리케이션을 보낼때 포트별로 체크하는 느낌...?!
따라서 tcp프로토콜은 손을 쓸수 없지만, udp는 애플리케이션에서 추가작업이 가능하다)
- PORT :
서버 안에서 돌아가는 어플리케이션을 구분해주는 역할이라고 이해하면 쉽다 !

기본 포트에 대해서 알아놓자.. !!

- DNS : 도메인 메인 시스템
- 도메인 명을 IP 주소로 변환해준다.
- 배포할때 DNS 서버에 연결해서 IP주소에 맞는 서버로 연결해줬던거 기억난다 !
Section2. URI와 웹 브라우저 요청 흐름
- URI (Uniform Resource Identifier)
- URI는 로케이터(Locator), 이름(Name) 또는 둘다 추가로 분류될 수 있다.
**uri, url, urn이 헷갈릴때 이 문장을 떠올려라 !

예시를 들어줄게 ~

url : 현재위치 urn: 고유이름
URI (Uniform Resource Identifier)
uniform : 리소스를 식별하는 통일된 방식
resource : 자원, uri로 식별할 수 있는 모든것
identifier : 다른 항목과 구분하는데 필요한 정보
URL (Uniform Resource Locator)
URN (UNiform Resource Name)

scheme : 프로토콜을 의미한다. (어떤 방식으로 자원에 접근할 것인가0
userinfo : url에 사용자 정보를 포함해서 인증해야할때, 요즘엔 거의 쓰지 않는다.
host : 호스트명, 도메인명 또는 ip주소를 직접 사용가능하다
port : 접속 포트를 의미한다. 일반적으로는 생략되고 http는 80 https는 443이다.
path : 리소스 경로이다 . /안에서 계층적 구조로 이루어진다.
query : key = value형태이고, ?로 시작되며 &로 추가가능하다. 보통 쿼리파라미터로 불린다.
fragment : 잘 사용하진 않지만 html내부 북마크 등에 사용한다. 서버에 전송하는 정보가 아니다.
- 웹 브라우저 요청 흐름
- 도메인을 땅! 입력하면 dns서버에서 ip로 변환한다
- 클라이언트는 http 메시지를 생성하지

- 웹브라우저에서 이렇게 생성된 메시지를 소켓 라이브러리를 통해 전달
- http 메시지가 포함된 tcp/ip 패킷이 생성된다
- 요청 패킷들이 수많은 인터넷 노드들을 통해 가게 된다..!
- 서버가 요청 패킷을 받고 http 응답 메시지를 보낸다

- 그리고 웹 브라우저 html 렌더링이 시작된다.
Section3. HTTP 기본
- HTTP:
HyperText Transfer Protocol
요즘엔 http 메시지에 html, text, image , 음성, 영상, json등 거의 모든 형태의 데이터를 주고 받는다.
현재는 HTTP/ 1.1 (1997년) 버전이 가장 많이 사용되고 우리에게 가장 중요한 버전.. !
하지만 기반 프로토콜은 이렇다.


- HTTP의 특징 :
클라이언트-서버의 구조,
무상태 프로토콜 (스테이트리스),
http 메시지,
단순함, 확장 가능

무상태는 아무서버나 호출해도 되기 때문에, http는 stateless상태를 유지한다.
비연결성으로 초 단위의 이하의 빠른 속도로 응답한다.
수천명이 동시에 서버 접속을 요청해도 실제 서버에서 동시에 처리하는 요청은 작다.
서버 자원을 효율적으로 사용할수 있다 (서버를 계속 연결하고 있지 않아도 되기 때문)
따라서 stateless 상태를 유지하기 위해, http 초기에는 연결, 종료가 반복되면서 낭비되었다.

하지만 지금은 http지속연결 (persistent connections)로 문제를 해결하였다.
- HTTP 메시지 :
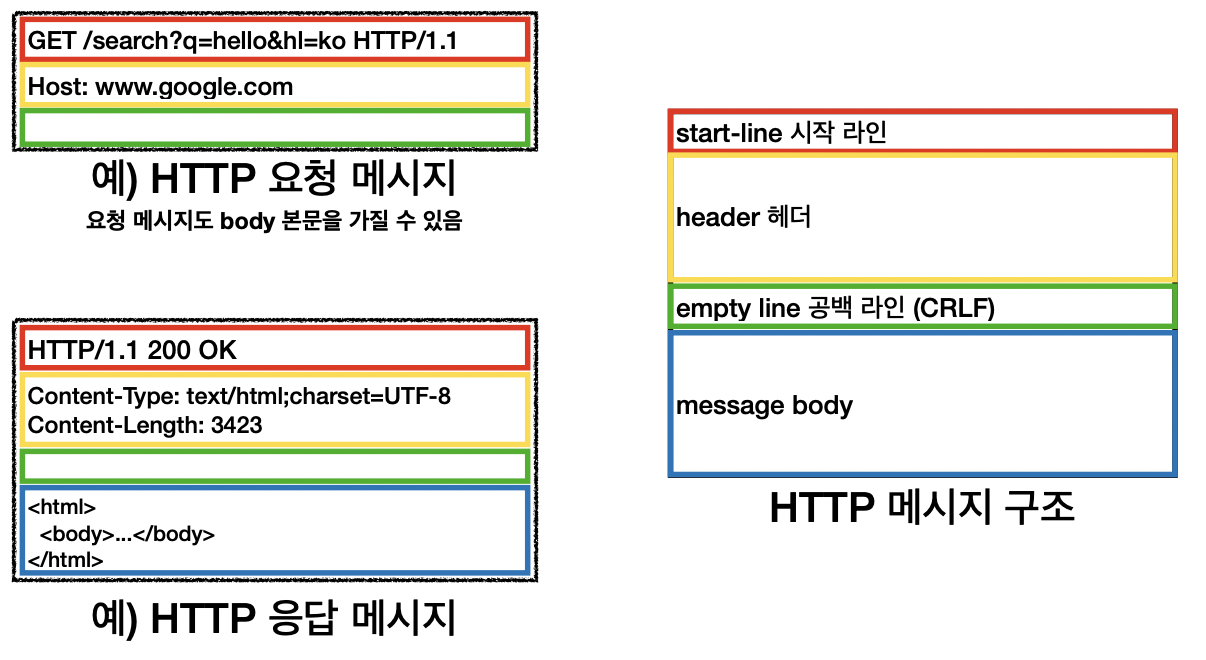
중요한 http헤더를 봐보자.. !!

그리고 우리가 실제로 주고받는 데이터는 http메시지 바디에 들어가있다 !
Section4. HTTP 메서드
- 만약 회원 정보 관리 api를 만든다면..?
회원 목록 조회/ 회원 조회 / 회원 등록 /. ..등등의 api를 만들어야겠지.
그러면 uri를 먼저 설계해보면
회원 목록 조회 / read-member-list,,
회원 조회/read-member-by-id..등
만들어봤다..좋은 설계일까?
uri설계에는 리소스의 의미를 담아야한다 !

이렇게 첫 uri설계는 리소스를 담고, 그리고나서
리소스와 행위를 분리해야한다.
- HTTP 메서드 종류 :


- GET :
리소스 조회. 서버에 전달하고 싶은 데이터는 쿼리파라미터를 통해서 전달.
예 ) 클라이언트의 GET 메시지 전달
GET/members/100 HTTP/1.1
HOST:localhost:8080예 ) 서버의 GET 메시지 응답
{
"username": "young",
"age":20
}
- POST :
메시지 바디를 통해 서버로 요청하는 데이터를 전달. 주로 신규 리소스 등록, 프로세스 처리
즉, 리소스 uri에 post요청이 오면 요청 데이터를 어떻게 처리할지 따로 정해야한다.
다음과 같은 경우가 있다.
1. 새 리소스 생성 (등록)
- 서버가 아직 식별하지 않은 새 리소스를 생성한다.
2. 요청 데이터 처리
- 단순 데이터 생성, 변경이 아닌 프로세스를 처리해야하는 경우
(주문에서 결제완료,,배달시작같은 프로세스 경우)
3. 다른 메서드로 처리하기 애매한 경우
- JSON으로 조회 데이터를 넘겨야 하는데 GET 메서드를 사용하기 어려운경우
(GET 메서드에서 메서드 바디를 허용하지 않은경우)
- PUT :
리소스가 있으면 대체, 리소스가 없으면 생성 ( 덮어버림 )
* 클라이언트가 리소스를 식별한다 (uri로 지정)
예) 리소스가 있는 경우의 PUT
// 클라이언트의 요청
PUT/members/100 HTTP/1.1 // 정확히 uri를 알고 멤버100에 이 내용을 보낼거야
Content-Type:application/json
{
"username": "old",
"age": 50
} //어떤 내용이 members/100에 담겨있건, 해당 바디메시지로 바뀌게 된다리소스가 없는 경우의 PUT은 (member/100이 없는경우) 는 그냥 100을 새로 생성하게 된다.
- PATCH :
기존 리소스가 있는 상태에서 PUT은 새로 덮어씌웠으나, 부분변경을 하기 위해 PATCH를 쓴다.

- HTTP 메서드의 속성 :
1. 안전 (Safe Methods)
안전은 해당 리소스가 안전한지만 고려한다.

2. 멱등(Idempotent Methods)
한 번 호출하든 두 번 호출하든 100번이든 결과가 똑같다.

따라서 멱등의 자동 복구 메커니즘에서 쓸수 있다.
( 서버가 timeout등으로 정상 응답을 못주었을 때, 클라이언트가 같은 요청을 다시 해도 되는가 ? 판단근거)
사실 잘 이해 못했다. 멱등의 정의와 활용을 찾아보자.
3. 캐시가능(Cacheable Methods)
응답 결과 리소스를 캐시해서 사용해도 되는가?
GET, HEAD, POST, PATCH 캐시가 가능하지만, GET과 HEAD 정도만 캐시로 사용한다.
Section5. HTTP 메서드 활용
- 클라이언트에서 서버로 데이터 전송 ?
- 쿼리 파라미터를 통한 데이터 전송 (GET, 정렬필터..)
- 메시지 바디를 통한 데이터 전송 (POST, PUT, PATCH..)
4가지 상황 ------------------------------------
1. 정적 데이터 조회 : 이미지, 정적 텍스트 문서 ( 리소스 path만 )
2. 동적 데이터 조회 : 검색, 게시판, 목록에서 정렬 필터 (주로 쿼리파라미터 사용)
3. HTML Form을 통한 데이터 전송 ( GET, POST만 전송가능하다)
회원가입, 상품조회 등 Content-Type : application/x-www-form-urlencoded 사용한다.
form의 내용을 메시지 바디를 통해서 전송하며, 데이터를 url에 인코딩 처리한다 (쿼리 파라미터 형식으로)
파일 업로드 같은 바이너리 데이터 전송시에는 Content-Type : multipart/form-data를 사용하여 전송가능하다
(당연히 메시지 바디를 사용한다 )

4. HTTP API를 통한 데이터 전송
자바스크립트 개발자인 내가, 거의 표준으로 쓰는 Content-Type : application/json 의 방법 !

** 알아두어야 할것
POST로 클라이언트에서 등록을 하게 되면 members/의 몇번인지 모르겠지!
그러니까 클라이언트는 리소스의 uri를 모르는겨, 서버가 생성해주고 응답해주지.
서버에서 이 리소스 디렉토리 관리는 컬렉션을 통해서 하고 , 컬렉션은 /members이다.
(프론트 개발자인 내가 구현하는 CRUD의 Create에 해당한다.)
PUT으로 클라이언트가 신규자원등록을 하게되면 클라이언트가 uri를 직접 지정해야한다.
클라이언트가 관리하는 리소스 저장소는 store이고, 여기서 리소스의 uri를 알고 관리한다.
(CRUD의 Update에 해당한다.)
Section6. HTTP 상태코드
이야 자료가 너무 잘되어있다. 상태코드 모르는거 나왔을때 찾아봐야지 지금 외울필욘 없으니까 ㅎ
** 추가로 알아둘 것
PRG 이후 리다이렉트
Section7. HTTP 헤더
- HTTP 전송에 필요한 모든 부가정보 ( 메시지 바디의 내용, 크기, 인증,등등....)
표준 헤더가 너무 많다. 필요시 임의의 헤더 추가가 가능하다.
HTTP 헤더의 분류중에 RFC2616이라는 과거의 표준이 있었다.
하지만 2014년 RFC7230 - 7235가 등장했다.

- 메시지 본문(페이로드 payload) 을 통해 표현 데이터를 전달한다.
- 표현은 요청이나 응답에서 전달할 실제 데이터
- 표현 헤더는 표현 데이터를 해석할 수 있는 정보를 제공하다.
- 표현 헤더의 내용 :
Content-Type: 표현 데이터의 형식
- 미디어 타입, 문자 인코딩 (text/html; charset=utf-8, application/json등)
Content-Encoding: 표현 데이터의 압축 방식
- 표현 데이터 인코딩,, (표현 데이터를 압축하기 위해 사용) 예 gzip, deflate..
Content-Language: 표현 데이터의 자연 언어
- 표현 데이터의 자연 언어를 표현 예 ko, en,,
Content-Length: 표현 데이터의 길이
- 바이트 단위
- 협상 (콘텐츠 네고시에이션): 클라이언트가 선호하는 표현 요청
- Accept: 클라이언트가 선호하는 미디어 타입 전달
- Accept- Charset : 클라이언트가 선호하는 문자 인코딩
- Accept - Encoding : 클라이언트가 선호하는 압축 인코딩
- Accept - Laguage : 클라이언트가 선호하는 자연언어
**서버에서 요청을 다 받아들이진 않을수 있지만, 선택사항에서 우선적으로 고려해준다.
-> 따라서, 우선순위를 지정하여 헤더에 보내줄수 있어야 한다.

이렇듯 문자 말고도, 미디어 타입과 문자 인코딩 선호도를 보낼 수 있다.
- 전송방식
1. 단순 전송 : content 길이를 알고, 단순히 요청 후 한번에 받는 것.
2. 압축 전송 : Content-Encoding : gzip이 된다. 무엇으로 압축되어있는지 알려줘야 인코딩 하니까.
3. 분할 전송 : Transfer -Encoding : chunked 가 들어가게 된다.
4. 범위 전송 : Range, Content-Range : bytes 1001 - 2000
- 일반정보
1. Form : 유저 에이전트의 이메일 정보
일반적으로 잘 사용되지 않으나, 검색엔진 같은 곳에서, 주로 사용
2. Referer : 이전 웹 페이지 주소
현재 요청된 페이지의 이전 웹 페이지 주소 A ->B로 이동하는 경우 A주소를 포함해서 요청
유입경로 분석 가능
3. User-Agent : 유저 에이전트 애플리케이션 정보
예) user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/ 537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
-> 클라이언트 애플리케이션 정보(웹 브라우저 정보, 등등)
4.Server : 요청을 처리하는 ORIGIN 서버의 소프트웨어 정보
- 특별한 정보
1. Host : 요청한 호스트 정보(도메인)
- 하나의 서버가 여러 도메인을 처리해야 할 때
- 하나의 IP 주소에 여러 도메인이 적용되어 있을 때
2. Location : 페이지 리다이렉션
-웹 브라우저는 3xx 응답의 결과에 로케이션 헤더가 있으면, 로케이션 위치로 자동 이동 (리다이렉트)
3. Retry-After : 503일때 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
- 인증
Authorizatoin : 클라이언트 인증 정보를 서버에 전달
WWW-Authenticate : 리소스 접근시 필요한 인증 방법 정의
- 쿠키
Set-Cookie : 서버에서 클라이언트로 쿠키 전달 (응답)
Cookie : 클라이언트가 서버에서 받은 쿠키를 저장하고, http 요청시 서버로 전달
http는 무상태 프로토콜이기 때문에, 클라이언트와 서버는 서로 상태를 유지하지 않는다.
하지만 요청할 때마다 인증 데이터를 포함할 수는 없기 때문에,

주로 사용처는 사용자 로그인 세션 관리, 광고 정보 트래킹
- 쿠키 정보는 항상 서버에 전송된다. 네트워크 트래픽이 추가로 유발될 수 있기 때문에, 서버에 전송하지 않고
웹 브라우저 내부에 데이터를 저장하고 싶으면 웹 스토리지를 잘 활용하자. (개인정보 주의)
쿠키에도 생명주기가 있어서 만료일을 지정해줄수 있다.
쿠키 도메인 : 아무 사이트나 들어갔을 때 나의 쿠키를 보내면 안되기 때문에, 명시한 문서 기준 도메인 + 서브 도메인 포함하여
해당 도메인만 접근 할 수 있도록 해야함
쿠키 경로 : 이 경로를 포함한 하위 경로 페이지만 쿠키 접근
쿠키 보안 :
secure(쿠키는 http, https를 구분하지 않고 전송),
httponly(xss공격방지, http 전송에만 사용),
samesite(XSRF 공격방지, 요청 도메인과 쿠키에 설정된 도메인이 같은 경우만 쿠키 전송)
Section8. HTTP 헤더2 - 캐시와 조건부 요청
- 캐시가 없을때
데이터가 변경되지 않아도 계속 네트워크를 통해서 데이터를 다운받아야한다.
브라우저 로딩속도가 느려질수 있기 때문에 느린 사용자 경험을 줄 수 있다.

이런식으로 적용되고, 해당 시간동안 접속하면 캐시데이터를 가져다가 쓴다.
하지만, 서버에서 기존 데이터가 변경되어버린 경우가 있기 때문에,
클라이언트 데이터와 서버의 데이터가 같다는 사실을 확인할 수 있는 방법이 필요하다.
-검증헤더추가
Last-modified: 서버에서 데이터가 마지막에 수정된 시간을 나타낸다
이후에 클라이언트에서 요청을 보낼때, if-modified-since에 해당 시간을 보내면,
서버의 Last-modified와 비교한다. 차이가 없다면 304와 http바디를 없이 보내준다 (나 데이터 바뀐거 없어!!@)

-> 검증 헤더와 조건부 요청의 정리
-캐시 유효 시간이 초과해도, 서버의 데이터가 갱신되지 않으면, 304 Not Modified + 헤더 메타 정보만 응답
-클라이언트는 서버가 보낸 응답 헤더 정보고 캐시의 메타 정보를 갱신
-클라이언트는 캐시에 저장되어 있는 데이터 재활용
- 검증헤더
-> 캐시 데이터와 서버 데이터가 같은지 검증하는 데이터
Last-Modified, ETag(캐시데이터의 임의의 고유한 버전 이름)
- 조건부 요청해더
->검증 헤더로 조건에 따른 분기,
If-Modified-Since (L-M사용), If-None-Match(ETag 사용)
-> 조건이 맞으면 200ok, 만족하지 않으면 304 Not modified
- 캐시와 관련된 조건부 요청해더
-Cache-Control : 캐시 제어
max-age, no-cache, no-store
-Pragma : 캐시 제어 (하위 호환)
-Expires : 캐시 유효 기간(하위 호환)
- 프록시 캐시 ( 프록시 서버에있는 프록시 캐시겠지 )
프록시 서버가 무엇인지 한눈에 보이는 그림 !

Cache-Control: public
응답이 public 캐시에 저장되어도 됨
Cache-Control: private
응답이 해당 사용자만을 위한 것임, private 캐시에 저장해야 함(기본값)
Cache-Control: s-maxage
프록시 캐시에만 적용되는 max-age
Age: 60 (HTTP 헤더)
오리진 서버에서 응답 후 프록시 캐시 내에 머문 시간(초)
- 그리고 절대 캐시가 되면 안되는 곳에서, 확실한 캐시 무효화를 하는 Cache-Control
